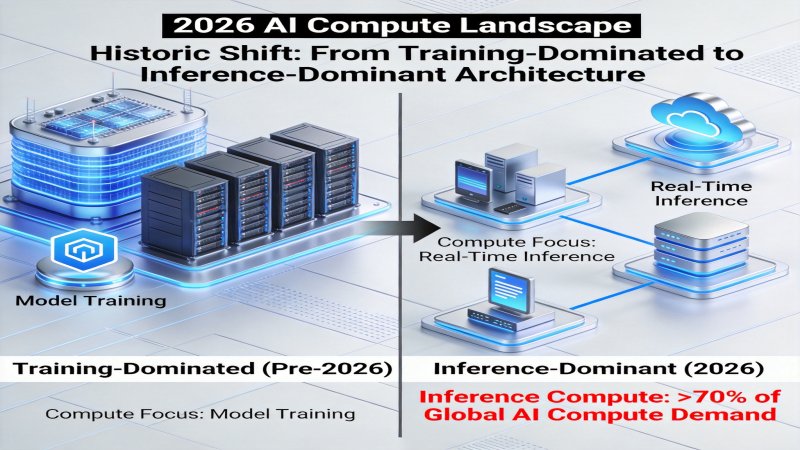
一、范式转变:从训练为王到推理主导
1.1 算力需求结构性重塑
2026年,人工智能基础设施领域正在经历一场深刻变革。根据最新行业数据,推理算力需求已占据全球AI算力总需求的70%以上,标志着AI计算从「训练主导」向「推理主导」的历史性转型。这一转变并非偶然,而是大模型规模化应用的必然结果——当模型训练完成后,每一次用户交互、每一轮对话、每一个API调用都需要消耗推理算力,而大模型的日活用户规模往往达到数百万甚至数亿级别。
这一结构性变化带来了深远影响:
- 成本重心迁移:CapEx(资本支出)从一次性训练投入,转向持续性推理运营成本
- 优化目标转变:从追求绝对性能转向追求单位Token成本最优
- 部署架构演进:从集中式云端训练集群,向分布式推理节点网络延伸
1.2 推理时代的竞争逻辑
当业界还在讨论参数规模竞赛时,真正的战场已经悄然转移——Token性价比正成为衡量AI基础设施竞争力的核心指标。这一指标综合考量了硬件采购成本、电力消耗、软件效率、吞吐量表现等多个维度,反映的是大模型服务的真实运营经济学。
正如SemiAnalysis在InferenceX报告中指出的,GB300 NVL72在FP4模式下实现了50 tokens/watt的效率,这一数字相较H100提升了50倍。这意味着每瓦特电力能够处理的Token数量增加了50倍,等同于成本降低35倍。对于日均处理数十亿Token的大规模推理服务而言,这一差异意味着每年数亿美元的运营成本节省。
二、硬件革新:三大厂商重定算力标准
2.1 NVIDIA GB300 NVL72:推理性能的量级飞跃
NVIDIA在2026年推出的GB300 NVL72系统代表了推理硬件的全新高度。这款基于Blackwell架构的平台实现了多项突破性创新:
| 指标 | GB300 NVL72 | 上一代H100 | 提升幅度 |
|---|---|---|---|
| 推理性能 | 基准的50倍 | 基准 | 50x |
| 量化支持 | FP4 | FP8 | 新一代精度 |
| 能效比 | 50 tokens/watt | 1 tokens/watt | 50x |
| 成本效率 | FP4下35x降低 | 基准 | 35x |
| 散热方案 | 85%液冷+15%风冷 | 混合散热 | 高密度适配 |
GB300 NVL72的核心竞争力在于其FP4量化能力。FP4是一种4位浮点精度格式,相比传统的FP16或FP8,能够在保持模型精度的前提下大幅减少计算和内存需求。NVIDIA通过硬件层面的原生支持,使得FP4量化不再是性能妥协的代名词,而是成为释放推理效率的密钥。
2.2 AMD MI355X:成本优化的AMD答卷
AMD在推理市场的布局同样咄咄逼人。MI355X凭借288GB HBM3E内存和FP8模式下的成本优势,为市场提供了差异化的选择。
AMD的策略聚焦于成本效率的极致优化。在FP8模式下,MI355X的成本表现与GB300相当,但在高交互场景下展现出独特的成本优势。这一优势源于AMD在内存带宽和计算密度之间的平衡设计——更大的HBM3E容量意味着更大的模型可以完整加载到显存中,减少了因模型分片带来的通信开销。
2.3 Google TPU v7:能效比的新标杆
Google TPU v7以100%全液冷设计和4614 TFLOPs的峰值算力,展现了云厂商自研芯片的独特路径。TPU v7的液冷设计不仅是散热方案的革新,更是对AIDC(AI数据中心)功率密度挑战的直接回应。
在功率密度方面,传统IDC的单机柜功率仅为4-8kW,而AIDC已跃升至10-100kW。NVIDIA GB200机柜功耗已达130-140kW,Vera Rubin GPU功耗更是飙升至2300W,顶配版本甚至达到3700W。在这一背景下,液冷从「可选配置」变为「必选方案」,而TPU v7的100%全液冷设计代表了面向未来的架构选择。
三、软件优化:效率革命的技术引擎
3.1 注意力机制革新:TurboQuant
Google发布的TurboQuant技术代表了KV缓存优化的重大突破。这项技术通过两项核心创新实现效率跃升:
- KV缓存压缩6倍:通过智能剪枝和量化技术,将Key-Value缓存的内存占用压缩至原来的1/6,显著降低显存需求
- 注意力计算加速8倍:优化注意力计算的数据流和并行策略,使注意力机制的算力消耗大幅降低
TurboQuant的创新意义在于,它不是通过牺牲模型精度来换取效率,而是在算法层面重新设计了注意力机制的实现方式。对于长上下文场景(如文档分析、长对话等),TurboQuant的价值尤为显著——这类场景恰恰是推理成本的主要来源。
3.2 架构范式创新:RWKV-6
RWKV-6的发布为推理优化提供了另一条技术路径。与Transformer架构不同,RWKV采用线性复杂度的注意力机制,从根本上改变了计算随序列长度增长的曲线。
| 指标 | Transformer架构 | RWKV-6架构 | 优势 |
|---|---|---|---|
| 注意力复杂度 | O(n2) | O(n) | 长序列优势显著 |
| 训练成本 | 基准 | 降低2-3倍 | 效率提升 |
| 推理成本 | 基准 | 降低2-10倍 | 规模化优势 |
| 内存占用 | O(n2) | O(n) | 显存需求降低 |
RWKV-6的开源策略进一步加速了其生态发展。线性复杂度的架构特性使其在边缘设备和低成本GPU上也能高效运行,为推理成本的极致优化提供了新选择。
3.3 推理框架进化:DTR与主流框架对比
SITS2026会议上发布的DTR(Dynamic Token Reduction)框架将推理优化推向新高度。实验数据显示,DTR框架能够将延迟降低至传统vLLM的37%,这一突破性的效率提升引发了业界的广泛关注。
当前推理服务框架呈现三足鼎立的格局:
| 框架 | 核心优势 | 适用场景 | 生态成熟度 |
|---|---|---|---|
| vLLM | PagedAttention、吞吐量高 | 大规模批量推理 | 5星 |
| SGLang | RadixAttention、长上下文优化 | 复杂多轮对话 | 4星 |
| TRT-LLM | TensorRT优化、低延迟 | 实时推理场景 | 4星 |
| DTR | 动态Token压缩、极致低延迟 | 超低延迟场景 | 3星 |
框架选择的关键在于理解业务场景的优先级——追求吞吐量选vLLM,优化长上下文选SGLang,极致低延迟选DTR或TRT-LLM。在实际部署中,很多团队采用多框架组合策略,根据不同业务线选择最合适的推理引擎。
四、市场机遇:推理优化赛道的黄金窗口
4.1 推理中间件市场爆发
推理中间件市场正经历从12亿美元向85亿美元规模的历史性扩张。这一市场的增长动力来自三个层面:
- 多模型路由需求:企业同时运营多个模型(GPT-4、Claude、Llama、本地模型等),需要智能路由层选择最优模型
- 负载均衡与弹性扩展:推理请求的波动性远大于训练,需要精细化的流量管理和资源调度
- API网关与成本控制:Token成本的可观测性和精细化控制成为运营刚需
预计到2027年,推理中间件市场年复合增长率将超过30%,成为AI基础设施领域增长最快的细分赛道之一。
4.2 边缘推理的爆发式增长
边缘推理正在重新定义AI算力的地理分布格局。数据显示,边缘算力占比正从15%快速提升至35%,年增长率超过60%。这一趋势的驱动力包括:
- 隐私合规要求:数据不出本地成为金融、医疗等行业的硬性要求
- 低延迟需求:自动驾驶、工业控制等场景对推理延迟的严格要求
- 成本优化:本地推理避免了云端数据传输和API调用的额外成本
边缘推理芯片市场呈现ASIC超越GPU的趋势。据预测,ASIC市场增长率达44%,远超GPU的16%。这一变化反映了边缘场景对专用化、低功耗推理芯片的强烈需求。
4.3 推理专用芯片的战略价值
推理专用芯片(ASIC)相比通用GPU在特定场景下展现出显著优势:
| 维度 | 推理ASIC | 通用GPU |
|---|---|---|
| 能效比 | 极高 | 较高 |
| 灵活性 | 有限 | 高 |
| 成本(推理场景) | 低 | 高 |
| 适用场景 | 固定模型、大规模部署 | 多模型、持续迭代 |
| 市场增长率 | 44% | 16% |
五、战略预判:Token性价比时代的五大趋势
5.1 FP4量化从实验走向生产
NVIDIA GB300 NVL72的量产将加速FP4量化技术的成熟。预计到2026年底,超过50%的大型推理集群将支持FP4推理模式,带动行业整体效率提升2-3个数量级。
5.2 推理中间件成为新基础设施层
如同云计算时代催生了Kubernetes等容器编排层,推理时代将催生新一代推理编排基础设施。市场格局尚未定型,存在巨大的创业和投资机会。
5.3 线性复杂度架构获得生产部署
RWKV等线性复杂度架构将突破「实验玩具」的标签,获得更多生产级部署。2-3倍的训练成本降低和2-10倍的推理成本优化,将吸引对成本敏感的大规模部署场景。
5.4 边缘推理芯片年增60%+
边缘推理芯片市场将维持60%以上的年增长率,ASIC市场份额将超过GPU,成为边缘AI的主导力量。国产推理芯片厂商有望在这一领域实现弯道超车。
5.5 Token性价比成为选型核心指标
Token性价比评估标准将取代传统TPS(每秒事务数)成为厂商选型的核心指标。企业IT采购将增加「性价比测试」环节,类似于传统的性能基准测试。
六、结论与建议
AI推理优化已从技术前沿演变为战略必争之地。在Token性价比主导的新时代,竞争的核心不再是单纯的算力堆砌,而是效率、成本、体验的综合最优解。
对于不同类型的参与者,我们提出差异化建议:
- 云服务商:加速液冷基础设施布局,优先测试FP4量化能力,抢占能效比制高点
- 企业用户:建立Token成本可观测性,采用多框架组合策略,根据业务场景选择最优架构
- 创业者和投资者:重点关注推理中间件、边缘推理芯片、KV缓存优化等细分赛道
- 开发者:深入掌握vLLM/SGLang等主流框架,积极跟进RWKV等新架构发展
历史的经验告诉我们,每一次计算范式的转移都会催生新的产业格局。推理时代的帷幕已经拉开,那些率先把握Token性价比密码的参与者,将在这场新的竞赛中占据先机。
💬 评论 (0)