1. Paradigm Shift: From Training-Dominated to Inference-Dominant
1.1 Structural Remodeling of Compute Demand
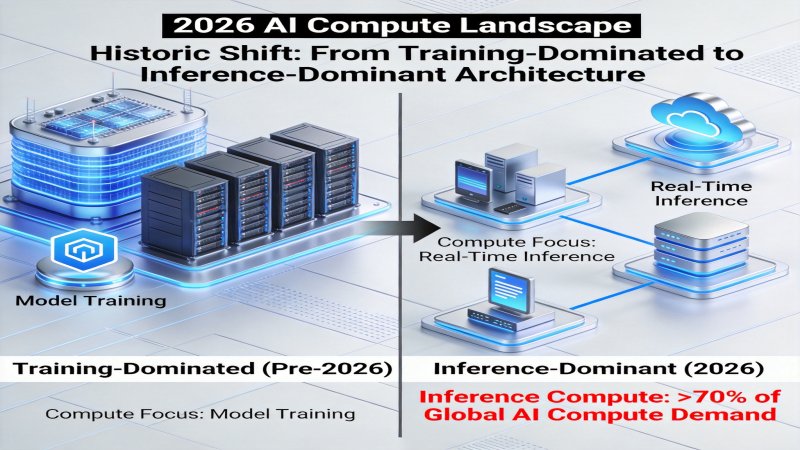
In 2026, the AI infrastructure sector is undergoing a profound transformation. According to latest industry data, inference compute demand now accounts for over 70% of global AI compute requirements, marking a historic shift from training-dominated to inference-dominant architecture. This transformation is not coincidental but an inevitable result of large-scale LLM application—when models are trained, every user interaction, every conversation turn, and every API call consumes inference compute, while daily active users of large models often reach tens of millions or even hundreds of millions.
This structural change brings far-reaching impacts:
- Cost focus migration: CapEx shifts from one-time training investment to continuous inference operational costs
- Optimization objective transformation: From pursuing absolute performance to optimizing cost-per-token
- Deployment architecture evolution: From centralized cloud training clusters to distributed inference node networks
1.2 The Logic of Competition in the Inference Era
While the industry is still debating parameter scale races, the real battlefield has quietly shifted—Token cost-performance is becoming the core metric for evaluating AI infrastructure competitiveness. This metric comprehensively considers hardware procurement costs, power consumption, software efficiency, throughput performance, and other dimensions, reflecting the true operational economics of LLM services.
As SemiAnalysis pointed out in the InferenceX report, GB300 NVL72 achieves 50 tokens/watt efficiency in FP4 mode, a 50x improvement over H100. This means the number of tokens processed per watt of electricity increases by 50x, equivalent to a 35x cost reduction. For large-scale inference services processing billions of tokens daily, this difference represents hundreds of millions of dollars in annual operational cost savings.
2. Hardware Innovation: Three Giants Redefine Compute Standards
2.1 NVIDIA GB300 NVL72: A Quantum Leap in Inference Performance
NVIDIA GB300 NVL72 system launched in 2026 represents a new height in inference hardware. This Blackwell-architecture-based platform achieves multiple breakthrough innovations:
| Metric | GB300 NVL72 | Previous Gen H100 | Improvement |
|---|---|---|---|
| Inference Performance | 50x baseline | Baseline | 50x |
| Quantization Support | FP4 | FP8 | Next-gen precision |
| Energy Efficiency | 50 tokens/watt | 1 tokens/watt | 50x |
| Cost Efficiency | FP4: 35x reduction | Baseline | 35x |
| Cooling Solution | 85% liquid + 15% air | Hybrid | High-density ready |
GB300 NVL72 core competitiveness lies in its FP4 quantization capability. FP4 is a 4-bit floating-point precision format that significantly reduces computation and memory requirements while maintaining model accuracy. NVIDIA native hardware support makes FP4 quantization not a compromise in performance but a key to unlocking inference efficiency.
2.2 AMD MI355X: AMD Answer to Cost Optimization
AMD layout in the inference market is equally aggressive. MI355X, with 288GB HBM3E memory and cost advantages in FP8 mode, provides a differentiated market choice.
AMD strategy focuses on extreme optimization of cost efficiency. In FP8 mode, MI355X cost performance is comparable to GB300, but shows unique cost advantages in high-interaction scenarios. This advantage stems from AMD balanced design between memory bandwidth and compute density—larger HBM3E capacity means larger models can be completely loaded into VRAM, reducing communication overhead from model sharding.
2.3 Google TPU v7: The New Benchmark for Energy Efficiency
Google TPU v7, with 100% liquid cooling design and 4614 TFLOPs peak compute, showcases the unique path of cloud vendors custom silicon. TPU v7 liquid cooling design is not just an innovation in cooling solutions but a direct response to AIDC (AI Data Center) power density challenges.
In terms of power density, traditional IDC single-rack power is only 4-8kW, while AIDC has jumped to 10-100kW. NVIDIA GB200 rack power reaches 130-140kW, Vera Rubin GPU power soars to 2300W, with top configurations reaching 3700W. In this context, liquid cooling has shifted from optional configuration to mandatory solution, and TPU v7 100% liquid cooling design represents a future-oriented architectural choice.
3. Software Optimization: The Technology Engine of Efficiency Revolution
3.1 Attention Mechanism Innovation: TurboQuant
Google TurboQuant technology represents a major breakthrough in KV cache optimization. This technology achieves efficiency leaps through two core innovations:
- 6x KV cache compression: Through intelligent pruning and quantization, Key-Value cache memory footprint is compressed to 1/6 of original, significantly reducing VRAM requirements
- 8x attention computation acceleration: Optimizing attention computation data flow and parallel strategies dramatically reduces attention mechanism compute consumption
TurboQuant innovative significance lies not in sacrificing model accuracy for efficiency, but in fundamentally redesigning the attention mechanism implementation at the algorithmic level. For long-context scenarios (such as document analysis, long conversations), TurboQuant value is particularly significant—these scenarios are precisely the primary sources of inference costs.
3.2 Architectural Paradigm Innovation: RWKV-6
RWKV-6 release provides another technical path for inference optimization. Unlike Transformer architecture, RWKV employs linear complexity attention mechanism, fundamentally changing the curve of compute growth with sequence length.
| Metric | Transformer Architecture | RWKV-6 Architecture | Advantage |
|---|---|---|---|
| Attention Complexity | O(n2) | O(n) | Superior for long sequences |
| Training Cost | Baseline | 2-3x reduction | Efficiency gain |
| Inference Cost | Baseline | 2-10x reduction | Scale advantage |
| Memory Footprint | O(n2) | O(n) | Lower VRAM demand |
RWKV-6 open-source strategy further accelerates its ecosystem development. The linear complexity architectural feature enables efficient operation on edge devices and low-cost GPUs, providing new choices for extreme inference cost optimization.
3.3 Inference Framework Evolution: DTR and Mainstream Framework Comparison
The DTR (Dynamic Token Reduction) framework released at SITS2026 pushes inference optimization to new heights. Experimental data shows that DTR framework can reduce latency to 37% of traditional vLLM, a breakthrough efficiency improvement that has attracted widespread industry attention.
The current inference service framework presents a tripartite confrontation:
| Framework | Core Advantage | Applicable Scenario | Ecosystem Maturity |
|---|---|---|---|
| vLLM | PagedAttention, high throughput | Large-scale batch inference | 5 stars |
| SGLang | RadixAttention, long-context optimization | Complex multi-turn conversations | 4 stars |
| TRT-LLM | TensorRT optimization, low latency | Real-time inference scenarios | 4 stars |
| DTR | Dynamic token compression, extreme low latency | Ultra-low latency scenarios | 3 stars |
The key to framework selection lies in understanding business scenario priorities—choose vLLM for throughput, SGLang for long context, DTR or TRT-LLM for extreme low latency. In actual deployment, many teams adopt multi-framework combination strategies, selecting the most suitable inference engine based on different business lines.
4. Market Opportunities: The Golden Window in Inference Optimization Track
4.1 Explosion of Inference Middleware Market
The inference middleware market is experiencing historic expansion from 1.2 billion USD to 8.5 billion USD. Growth drivers come from three levels:
- Multi-model routing demand: Enterprises operating multiple models simultaneously need intelligent routing layers to select optimal models
- Load balancing and elastic scaling: Inference request volatility far exceeds training, requiring fine-grained traffic management and resource scheduling
- API gateway and cost control: Token cost observability and fine-grained control become operational necessities
By 2027, the inference middleware market CAGR is expected to exceed 30%, becoming one of the fastest-growing segments in AI infrastructure.
4.2 Explosive Growth of Edge Inference
Edge inference is redefining the geographic distribution of AI compute. Data shows edge compute proportion is rapidly increasing from 15% to 35%, with annual growth exceeding 60%. Drivers of this trend include:
- Privacy compliance requirements: Data not leaving local environment becomes a hard requirement for finance, healthcare and other industries
- Low latency demand: Strict inference latency requirements for autonomous driving, industrial control and other scenarios
- Cost optimization: Local inference avoids cloud data transmission and API call overhead
The edge inference chip market shows a trend of ASICs surpassing GPUs. According to forecasts, the ASIC market growth rate reaches 44%, far exceeding GPU 16%. This change reflects strong demand for specialized, low-power inference chips in edge scenarios.
4.3 Strategic Value of Inference-Specific Chips
Inference-specific chips (ASICs) show significant advantages over general-purpose GPUs in specific scenarios:
| Dimension | Inference ASIC | General GPU |
|---|---|---|
| Energy Efficiency | Extremely high | Relatively high |
| Flexibility | Limited | High |
| Cost (Inference) | Low | High |
| Applicable Scenario | Fixed models, large-scale deployment | Multi-model, continuous iteration |
| Market Growth Rate | 44% | 16% |
5. Strategic Predictions: Five Trends in the Token Cost-Performance Era
5.1 FP4 Quantization Moves from Experiment to Production
NVIDIA GB300 NVL72 mass production will accelerate FP4 quantization technology maturation. By end of 2026, over 50% of large inference clusters will support FP4 inference mode, driving industry-wide efficiency improvements of 2-3 orders of magnitude.
5.2 Inference Middleware Becomes New Infrastructure Layer
Like how the cloud computing era gave birth to container orchestration layers like Kubernetes, the inference era will spawn a new generation of inference orchestration infrastructure. Market structure is not yet fixed, presenting huge entrepreneurial and investment opportunities.
5.3 Linear Complexity Architecture Gains Production Deployment
Linear complexity architectures like RWKV will break through the experimental toy label and gain more production-level deployments. 2-3x training cost reduction and 2-10x inference cost optimization will attract cost-sensitive large-scale deployment scenarios.
5.4 Edge Inference Chips Grow 60%+ Annually
The edge inference chip market will maintain over 60% annual growth, with ASIC market share exceeding GPUs to become the dominant force in edge AI. Domestic inference chip vendors are expected to achieve overtaking in this field.
5.5 Token Cost-Performance Becomes Core Selection Criterion
Token cost-performance evaluation standards will replace traditional TPS (Transactions Per Second) as the core vendor selection criterion. Enterprise IT procurement will add cost-performance testing phases, similar to traditional performance benchmarking.
6. Conclusion and Recommendations
AI inference optimization has evolved from a technical frontier to a strategic battleground. In the new era dominated by Token cost-performance, the core of competition is no longer sheer compute power stacking but the comprehensive optimal solution of efficiency, cost, and experience.
For different types of participants, we offer differentiated recommendations:
- Cloud service providers: Accelerate liquid cooling infrastructure deployment, prioritize FP4 quantization capability testing, seize energy efficiency high ground
- Enterprise users: Establish Token cost observability, adopt multi-framework combination strategies, select optimal architecture based on business scenarios
- Entrepreneurs and investors: Focus on inference middleware, edge inference chips, KV cache optimization and other segments
- Developers: Master major frameworks like vLLM/SGLang, actively follow RWKV and other new architecture developments
Historical experience tells us that every computing paradigm shift births new industrial landscapes. The curtain of the inference era has risen; those who first master the Token cost-performance code will secure first-mover advantage in this new competition.
Why it Matters
DECISION
PREDICT
Get 3-5 key AI infrastructure signals weekly →
💬 Comments (0)