推理不再是训练的副产品——它就是主战场
2026年5月,三条信号同时抵达,指向同一个结论:AI基础设施的竞争重心已经从「谁训练得更快」转向「谁推理得更便宜」。
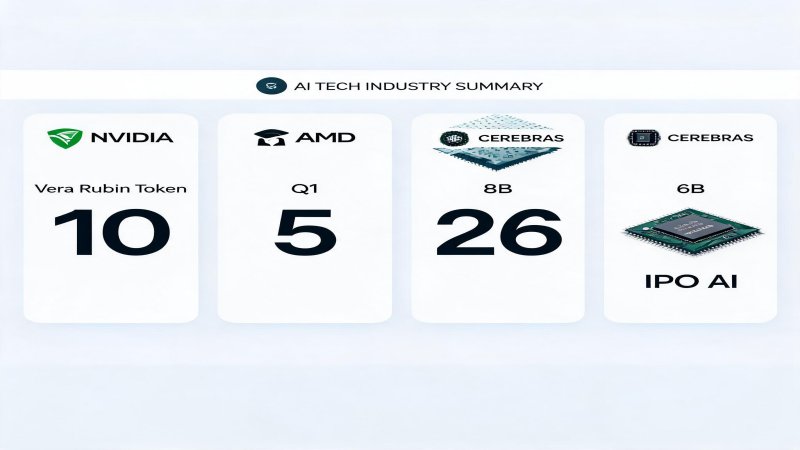
AMD Q1财报数据中心收入$5.8B(+57% YoY),MI300X单季收入超$50亿,CEO苏姿丰直接表态「智能体正在引爆AI巨大需求」✅已验证。NVIDIA在GTC 2026发布Vera Rubin七芯片一体化平台,宣称推理成本/token降低10倍,$1万亿订单锁定至2027✅已验证。Cerebras以$26.6B估值启动IPO路演,WSE-3晶圆级芯片推理速度达NVIDIA 21倍,5月13日定价✅已验证。
这不是三个独立事件,而是一个结构性转折的三个切面。
从卖GPU到卖AI工厂:NVIDIA的推理优先架构
Vera Rubin不是一次迭代,而是一次架构哲学的转向。NVIDIA不再卖GPU,开始卖整个AI推理工厂。
Vera CPU——Agent编排从GPU卸载。88核Arm,227B晶体管,1.5TB LPDDR5X(3x前代Grace)。一个MGX机架256颗Vera CPU=22,500核+400TB内存。NVIDIA的论点是:别把Agent编排、上下文管理、工具路由这些逻辑烧GPU算力,让CPU做Agent逻辑,GPU做数学。这是一个架构论点,不只是产品。
Rubin GPU——为吞吐量而非峰值FLOPS设计。3nm,336B晶体管,50 PFLOPS FP4(5x Blackwell),288GB HBM4 + 22 TB/s带宽(2.8x Blackwell)。关键不是峰值算力,而是2.8倍内存带宽提升——大规模推理是memory-bound,不是compute-bound。NVIDIA深谙此道,Rubin的设计哲学就是围绕这个约束展开。
Groq 3 LPU——NVIDIA花$20B收购的推理加速器。每颗LPU 500MB SRAM,150 TB/s带宽,1.2 PFLOPS FP8。256-LPU机架128GB SRAM,40 PB/s聚合带宽。NVIDIA声称推理吞吐/MW比Blackwell高35倍⚠️厂商宣称。如果你的商业模式依赖推理成本/token,你的单位经济模型刚刚被重写。
AMD:推理需求的第一个硬证据
AMD的Q1数字不是「也不错」,而是「真的可以」——四大超大规模客户(Microsoft/Meta/Google/Oracle)全面部署MI300X,MI300X Instinct GPU单季收入超$50亿✅已验证。Q2指引$11.2B超预期7%。
但AMD的短板同样清晰:HBM供应仍是瓶颈,Samsung/SK Hynix的产能分配优先NVIDIA。AMD攻的是推理性价比,NVIDIA攻的是推理绝对性能——两条不同路线,但都在押注同一个结论:推理是增量市场。
Cerebras:专用推理芯片的公开市场测试
$26.6B估值,$510M收入,52x PS——这是市场对「NVIDIA替代方案」定价权的第一次公开测试。Cerebras的核心赌注是晶圆级芯片:46,225mm²单片晶圆,4T晶体管,900K AI核心,44GB片上SRAM,21 PB/s带宽——模型权重全在片上,无需DRAM访问。推理速度1,800-2,100 tokens/sec(vs H100 ~90-150 tokens/sec)✅已验证。
但风险不容忽视:OpenAI占未来收入「substantial portion」(客户集中度风险),TSMC单一供应风险,92x PS估值在市场回调时极为脆弱。
薄弱点:电力基础设施——推理战争的真正瓶颈
芯片竞赛打得火热,但物理世界的约束正在显形。美国50%+的2026数据中心项目延期/取消,140个项目规划16GW,仅5GW在建✅已验证(Bloomberg/Power Magazine)。变压器交期从2020年前的24-30个月延长至3-5年。算力需求指数增长,但电力基础设施3-5年交付周期——供需时间错配是2026-2028最大结构性风险。
$650B资金到位,但物理交付无法加速。推理芯片再快,没有电就是废铁。
预判
1. 推理成本/token将在18个月内下降10-50倍(Vera Rubin 10x + Rubin Ultra 5-10x),企业部署大规模Agent的算力经济性将在2027年H1出现拐点⚠️高置信度
2. Cerebras IPO定价将决定专用推理芯片赛道的估值锚——成功则利好Groq/SambaNova,失败则强化NVIDIA GPU不可替代性。5月13日见分晓⚠️高置信度
3. 电力基础设施(变压器/开关设备)将成为2026-2028最确定性投资主线——Eaton扩产、Vertiv股价大涨、中国变压器出口+36%已在反映这一趋势✅已验证
💬 评论 (0)