Inference Is No Longer the Afterthought — It Is the Battlefield
Three signals arrived simultaneously in May 2026, all pointing to the same conclusion: the center of gravity in AI infrastructure has shifted from who trains faster to who infers cheaper.
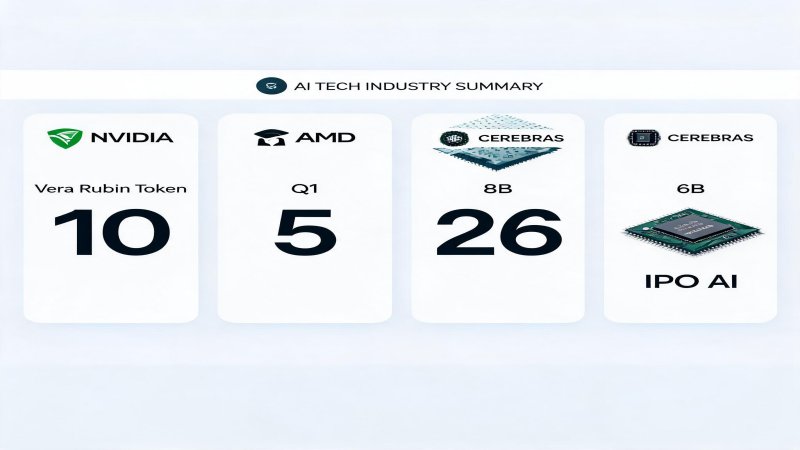
AMD Q1 earnings: data center revenue $5.8B (+57% YoY), MI300X clearing $5B in a single quarter across all four hyperscalers, CEO Lisa Su declaring agents are igniting massive AI demand ✅Verified. NVIDIA Vera Rubin at GTC 2026: a seven-chip inference platform claiming 10x lower cost per token, with $1 trillion in orders locked through 2027 ✅Verified. Cerebras launching its IPO roadshow at $26.6B valuation, with WSE-3 waferscale inference at 21x NVIDIA speed, pricing May 13 ✅Verified.
These are not three independent events. They are three facets of a structural inflection.
From Selling GPUs to Selling AI Factories: NVIDIA Inference-First Architecture
Vera Rubin is not an iteration — it is a philosophical shift. NVIDIA is no longer selling GPUs. It is selling the entire AI inference factory.
Vera CPU — Agent orchestration, offloaded from GPUs. 88-core Arm, 227B transistors, 1.5TB LPDDR5X (3x Grace). An MGX rack with 256 Vera CPUs delivers 22,500 cores and 400TB of memory. NVIDIA argument: stop burning GPU cycles on orchestration, context management, and tool routing. Let the CPU handle agent logic; let the GPU handle math. That is an architectural thesis, not just a product.
Rubin GPU — Built for throughput, not peak FLOPS. 3nm, 336B transistors, 50 PFLOPS FP4 (5x Blackwell), 288GB HBM4 + 22 TB/s bandwidth (2.8x Blackwell). The key is not peak compute — it is the 2.8x memory bandwidth uplift. Large-scale inference is memory-bound, not compute-bound. NVIDIA knows this, and Rubin is designed around that constraint.
Groq 3 LPU — The inference accelerator NVIDIA acquired for $20B. Each LPU packs 500MB SRAM with 150 TB/s bandwidth and 1.2 PFLOPS FP8. A 256-LPU rack delivers 128GB SRAM and 40 PB/s aggregate bandwidth. NVIDIA claims 35x inference throughput per MW versus Blackwell ⚠️Vendor claim. If your business model depends on inference cost per token, your unit economics just got rewritten.
AMD: The First Hard Evidence of Inference Demand
AMD Q1 numbers are not also decent — they are actually credible. All four hyperscalers (Microsoft, Meta, Google, Oracle) are deploying MI300X, with the Instinct GPU clearing $5B in a single quarter ✅Verified. Q2 guidance of $11.2B came in 7% above consensus.
But the gap is equally clear: HBM supply remains a bottleneck, with Samsung and SK Hynix capacity allocation favoring NVIDIA. AMD attacks inference price-performance; NVIDIA attacks inference absolute performance. Two different routes, same bet: inference is the growth market.
Cerebras: The Public Market Test for Dedicated Inference Silicon
$26.6B valuation on $510M revenue — 52x price-to-sales. This is the first public market test for pricing the NVIDIA alternative. Cerebras core bet is waferscale: 46,225mm² single-die wafer, 4T transistors, 900K AI cores, 44GB on-chip SRAM, 21 PB/s bandwidth — model weights entirely on-chip, no DRAM access needed. Inference speed: 1,800-2,100 tokens/sec vs H100 ~90-150 ✅Verified.
But risks are real: OpenAI accounts for a substantial portion of future revenue (customer concentration), TSMC single-source risk, and 92x PS is extremely fragile in a market downturn.
Weak Point: Power Infrastructure — The Real Bottleneck of the Inference War
The chip race is blazing, but physical-world constraints are materializing. 50%+ of US 2026 data center projects are delayed or canceled, 140 projects planning 16GW with only 5GW under construction ✅Verified (Bloomberg/Power Magazine). Transformer lead times have stretched from 24-30 months pre-2020 to 3-5 years. Compute demand is exponential; power infrastructure delivery is linear at best — the time mismatch is the biggest structural risk of 2026-2028.
$650B in capital is committed, but physics cannot be accelerated. The fastest inference chip in the world is worthless without power.
Predictions
1. Inference cost per token will drop 10-50x within 18 months (Vera Rubin 10x + Rubin Ultra 5-10x). The unit economics of deploying large-scale AI agents will hit an inflection point in H1 2027 ⚠️High confidence
2. Cerebras IPO pricing will set the valuation anchor for the dedicated inference silicon sector — success benefits Groq/SambaNova, failure reinforces NVIDIA GPU irreplaceability. May 13 will tell ⚠️High confidence
3. Power infrastructure (transformers, switchgear) will be the highest-conviction investment theme of 2026-2028 — Eaton capacity expansion, Vertiv stock surge, and China transformer exports +36% already reflect this trend ✅Verified
Why it Matters
DECISION
PREDICT
Get 3-5 key AI infrastructure signals weekly →
💬 Comments (0)